
Wikimedia-Apps/Team/Android/Maschinenunterstützte Artikelbeschreibungen/Updates
Updates
Further changes
- We've used the same underlying machine-learning model for all of these experiments (so no re-training etc. of the actual model). What we've been adjusting throughout is how the user interacts with it.
- Our initial offline evaluation was of this model (Jan-April '23) lead us to put in place a few modifications to how users interacted with the model for the May-June 2023 piloting -- notably which outputs they could see (only higher confidence ones) and adjusting who could see the recommendations based on whether the article was a biography of a living person or not.
- The feedback from that pilot lead to us putting in place one final adjustment having to do with when a recommended article description included a year in it (only show it if there's support for that year in the article text because this was one source of hallucinations by the model). That's now part of the officially deployed model on LiftWing (the link I shared above) that Android users would see.
- At this point we aren't planning on any model updates beyond trying to reduce the latency of the model so Android users can see the recommendations more quickly. If we got feedback about errors that we thought we could address though, we'd try to make those fixes
August 2024
- We are beginning to reach out to some Wikis to implement the feature, based on the results from the experiment that was updated and published last January.
July 2024: API available through LiftWing
We appreciate everyone's patience as we've worked with the Machine Learning team to migrate the model to LiftWing. In August we will clean up the client side code to remove test conditions and add in improvements mentioned in the January 2024 update. In the following months we will reach out to different language communities to make the feature available to them in the app.
If you are a developer and would like to build a gadget using the API, you can read the documentation here.
Januar 2024: Ergebnisse des Experiments
Für die Bewertung berücksichtigte Sprachen:
- Arabisch
- Tschechisch
- Deutsch
- Englisch
- Spanisch
- Französisch
- Gujarati
- Hindi
- Italienisch
- Japanisch
- Russisch
- Türkisch
Zusätzliche Sprachen, die von Mitarbeitenden geprüft werden, die keine Bewerter:innen aus der Community haben:
- Finnisch
- Kasachisch
- Koreanisch
- Burmesisch
- Niederländisch
- Rumänisch
- Vietnamesisch
Gab es einen Unterschied zwischen den durchschnittlichen und mittleren Bewertungen maschinell akzeptierter und menschlicher Bearbeitungen:
| Bewertete Bearbeitungen | Durchschnittliche Bewertung | Mittlere Bewertung |
| Maschinell akzeptierte Bearbeitungen | 4,1 | 5 |
| Menschliche Bearbeitungen | 4,2 | 5 |
- Hinweis: 5 war die höchstmögliche Bewertung
Wie hat sich das Modell über alle Sprachen hinweg geschlagen?
| Sprache | Maschinell akzeptiert
Durchschnittliche Bewertung der Bearbeitungen |
Menschlich
Durchschnittliche Bewertung der Bearbeitungen |
Maschinell
Höhere Bewertung? |
Empfehlung, ob die Funktion aktiviert werden sollte |
| ar* | 2,8 | 2,1 | WAHR | Nein |
| cs | 4,5 | Nicht zutreffend | Ja | |
| de | 3,9 | 4,1 | FALSCH | 50+ Bearbeitungen benötigt |
| en | 4,0 | 4,5 | FALSCH | 50+ Bearbeitungen benötigt |
| es | 4,5 | 4,1 | WAHR | Ja |
| fr | 4,0 | 4,1 | FALSCH | 50+ Bearbeitungen benötigt |
| gu* | 1,0 | Nicht zutreffend | Nein | |
| hi | 3,8 | Nicht zutreffend | 50+ Bearbeitungen benötigt | |
| it | 4,2 | 4,4 | FALSCH | 50+ Bearbeitungen benötigt |
| ja | 4,0 | 4,5 | FALSCH | 50+ Bearbeitungen benötigt |
| ru | 4,7 | 4,3 | WAHR | Ja |
| tr | 3,8 | 3,4 | WAHR | Ja |
| Andere Sprachcommunitys | Nicht zutreffend | Nicht zutreffend | Nicht zutreffend | Kann auf Anfrage aktiviert werden |
- Hinweis: Wir werden die Funktion nicht aktivieren, ohne die Community zuerst einzubinden.
* Gibt Sprachcommunitys an, in denen es nicht viele Vorschläge zur Bewertung gab, was nach unserer Einschätzung einen Einfluss auf die Punktzahl hatte.
Wie oft wurden maschinelle Vorschläge übernommen, angepasst oder abgelehnt?
| Kategorie der Bearbeitung | % der gesamten maschinellen Bearbeitungen |
| Übernommener maschineller Vorschlag | 23,49 % |
| An gepasster maschineller Vorschlag | 14,49 % |
| Abgelehnter maschineller Vorschlag | 62,02 % |
- Hinweis: Ablehnung bedeutet, dass der maschinelle Vorschlag nicht ausgewählt wurde, obwohl er angeboten wurde. Die maschinellen Vorschläge wurden explizit als solche benannt. Benutzer:innen, die die maschinellen Vorschläge überhaupt nicht betrachtet hatten, zählen zur Kategorie „abgelehnt“. Die Ablehnung gibt an, dass Benutzer:innen stattdessen lieber eine eigene Artikel-Kurzbeschreibung geschrieben haben.
Wie waren übernommene maschinell akzeptierte Artikel-Kurzbeschreibungen, die mit 3 oder höher bewertet wurden, verteilt?
| Bewertung | Prozentuelle Verteilung |
| < 3 | 10,0 % |
| >= 3 | 90,0 % |
Wie hat sich die Bewertung der maschinell akzeptierten Artikel-Kurzbeschreibungen verändert, wenn die Erfahrung der Bearbeitenden berücksichtigt wird?
| Bearbeitungserfahrung | Durchschnittliche Bewertung der Bearbeitungen | Mittlere Bewertung der Bearbeitungen |
| Weniger als 50 Bearbeitungen | 3,6 | 4 |
| Mehr als 50 Bearbeitungen | 4,4 | 5 |
In unserem Experiment wurden zwei Gruppen getestet, um zu sehen, welche genauer und leistungsstärker ist. Um Voreingenommenheit zu vermeiden, wurde die Positionierung des Vorschlags für die Benutzer:innen jedes Mal gewechselt. Die Ergebnisse sind:
| Gewählte Gruppe | Durchschnittliche Bewertung der Bearbeitungen | %-Verteilung |
| 1 | 4,2 | 64,7 % |
| 2 | 4,0 | 35,3 % |
- Hinweis: Bei der Aktivierung der Funktion werden wir nur Gruppe 1 anzeigen.
Wie oft nehmen Menschen Änderungen am maschinellen Vorschlag vor, bevor sie ihn übernehmen?
| Art der Bearbeitung | Verteilung von Änderungen |
| Maschinell akzeptiert, unverändert | 61,85 % |
| Maschinell akzeptiert, verändert | 38,15 % |
Wie wirken sich Benutzer:innen, die maschinelle Vorschläge verändern, auf die Genauigkeit aus?
| Maschinell bewertete Bearbeitungen | Durchschnittliche Bewertung |
| Unverändert | 4,2 |
| Verändert | 4,1 |
- Hinweis: Da es keine Auswirkungen auf die Genauigkeit hat, wenn Benutzer:innen den Vorschlag ändern, sehen wir keine Notwendigkeit, von ihnen zu verlangen, eine Änderung am Vorschlag vorzunehmen, aber wir sollten dennoch eine Oberfläche bereitstellen, die Änderungen der maschinellen Vorschläge fördert.
Wie oft haben Bewerter:innen angegeben, dass sie eine Bearbeitung zurücksetzen oder überarbeiten würden, je nachdem, ob sie maschinell vorgeschlagen oder von Menschen getätigt wurden?
| Bewertete Bearbeitungen | % der Bearbeitungen zurücksetzen | % der Bearbeitungen überarbeiten |
| Autor:in übernahm Vorschlag | 2,3 % | 25,0 % |
| Autor:in sah Vorschlag, aber schrieb eigene Kurzbeschreibung | 5,7 % | 38,4 % |
| Menschliche Bearbeitung ohne Vorschlag | 15,0 % | 25,8 % |
- Hinweis: Wir haben „Zurücksetzen“ so definiert, dass die Bearbeitung so ungenau ist, dass es sich beim Sichten nicht lohnt, eine kleine Änderung zur Verbesserung vorzunehmen. „Überarbeiten“ wurde so definiert, dass Sichter:innen mit einer eigenen Bearbeitung verbessern, was von Benutzer:innen veröffentlicht wurde. Im Laufe des Experiments wurden nur 20 maschinelle Bearbeitungen in allen Projekten zurückgesetzt, was statistisch unerheblich war, sodass wir die tatsächlichen Zuücksetzungen nicht vergleichen konnten. Stattdessen haben wir uns auf Empfehlungen der Bewerter:innen bezogen. Nur zwei Sprachcommunitys pflegen ihre Artikel-Kurzbeschreibungen direkt auf Wikipedia, was bedeutet, dass Kontrollen für die meisten Sprachcommunitys weniger häufig vorkommen, da die Beschreibungen sich auf Wikidata befinden.
Welche Erkenntnisse haben wir durch die Meldefunktion des Werkzeugs gewonnen?
0,5 % individueller Benutzer:innen haben eine Meldung vorgenommen. Unten werden die erhaltenen Rückmeldungen nach Art aufgeschlüsselt:
| Rückmeldung | %-Verteilung der Rückmeldung |
| Zu wenig Information | 43 % |
| Unpassender Vorschlag | 21 % |
| Falsche Daten | 14 % |
| Beschreibung nicht sichtbar | 7 % |
| „Unnötige Sonderfunktion“ | 7 % |
| Falsch geschrieben | 7 % |
Wirkt sich die Funktion auf die Bindung von Benutzer:innen aus?
| Bindungsdauer | Gruppe 0
(Ohne die Funktion) |
Gruppen 1 und 2 |
| Durchschnittliche Rückkehrrate innerhalb eines Tages: | 35,4 % | 34,9 % |
| Durchschnittliche Rückgaberate innerhalb von drei Tagen: | 29,5 % | 30,3 % |
| Durchschnittliche Rückkehrrate innerhalb von sieben Tagen: | 22,6 % | 24,1 % |
| Durchschnittliche Rückkehrrate innerhalb von 14 Tagen: | 14,7 % | 15,8 % |
- Hinweis: Benutzer:innen, die Artikeln mit maschinell unterstützten Kurzbeschreibungen ausgesetzt waren, hatten eine geringfügig höhere Rückkehrrate im Vergleich zu Benutzer:innen, die nicht mit der Funktion zu tun hatten.
Nächste Schritte:
Das Experiment wurde über die Cloud-Services durchgeführt, was keine nachhaltige Lösung ist. Es gibt genügend positive Messgrößen, um die Funktion Communitys bereitzustellen, die es sich wünschen. Das App-Team wird mit unserem Bereich für maschinelles Lernen zusammenarbeiten, um das Modell nach Liftwing zu migrieren. Danach wird es umfassend auf seine Leistung getestet, dann werden wir wieder auf unsere Sprachcommunitys zugehen, um festzustellen, wo wir die Funktion aktivieren und welche zusätzlichen Verbesserungen wir am Modell vornehmen können. Anpassungen, die wir aktuell im Blick haben, sind unter anderem:
- Ausschluss von Biografien lebender Personen: Während des Experiments erlaubten wir Benutzer:innen mit über 50 Bearbeitungen, mit maschineller Hilfe Kurzbeschreibungen zu Biografien lebender Personen hinzuzufügen. Uns ist bewusst, dass es Bedenken gibt, wenn durchgehend Artikel-Kurzbeschreibungen zu diesen Artikeln vorgeschlagen werden. Wir haben zwar keine konkreten Hinweise auf Probleme im Zusammenhang mit Biografien lebender Personen gesehen, können aber selbstverständlich Vorschläge für diese Artikel abstellen.
- Nutzung von Gruppe 1: Gruppe 1 hat bei Vorschlägen immer bessere Ergebnisse erzielt als Gruppe 2. Wir werden daher nur eine Empfehlung anzeigen, nämlich jene aus Gruppe 1.
- Anpassung der Einführung und Anleitung: Während des Experiments haben wir eine Einführungsübersicht zu maschinellen Vorschlägen gezeigt. Wir würden bei der erneuten Veröffentlichung der Funktion eine Anleitung zu maschinellen Vorschlägen hinzufügen. Es wäre hilfreich, Rückmeldungen von der Community zu bekommen, welche Anleitung wir Benutzer:innen anbieten sollen, damit sie effektive Artikel-Kurzbeschreibungen schreiben, sodass wir die Einführung verbessern können.
Wenn es andere offensichtliche Fehler gibt, hinterlasse bitte eine Nachricht auf unserer Projekt-Diskussionsseite, damit wir diese beheben können. Ein Beispiel für einen offensichtlichen Fehler ist die Anzeige falscher Datumsangaben. Wir haben diesen Fehler während der Tests in der App bemerkt und einen Filter hinzugefügt, der Empfehlungen verhindert, die Daten enthalten, die nicht im Artikeltext erwähnt werden. Wir haben auch festgestellt, dass die Begriffklärungsseiten vom ursprünglichen Modell noch berücksichtigt wurden, und deshalb Begriffsklärungsseiten clientseitig herausgefiltert, was wir weiterhin so handhaben möchten. Andere Dinge wie die Großschreibung des ersten Buchstabens können wir auch allgemein lösen, da es klare Beurteilungskriterien zur Umsetzung gibt.
Für Sprachen, in denen das Modell nicht gut genug ist, um es zu aktivieren, ist es am nützlichsten, mehr Artikel-Kurzbeschreibungen in dieser Sprache hinzuzufügen, damit dem Modell für die Zukunft mehr Trainingsdaten zur Verfügung stehen. Es gibt kein festgelegtes Datum oder eine bestimmte Frequenz für zukünftiges Training, aber wir können mit dem Team für Forschung und maschinelles Lernen zusammenarbeiten, um dies zu priorisieren, wenn die Communitys es wünschen.
July 2023: Early Insights from 32 Days of Data Analysis: Grading Scores and Editing Patterns
We can not complete our data analysis until all entries have been graded so that we have an accurate grading score. However we do have early insights we can share. These insights are based on 32 days of data:
- 3968 Articles with Machine Edits were exposed to 375 editors.
- Note: Exposed does not mean selected.
- 2125 Machine edits were published by 256 editors
- Editors with 50+ edits completed three times the amount of edits per unique compared to editors with less than 50 edits
May 2023: Experiment Deactivated & Volunteers Evaluate Article Short Descriptions
The experiment has officially been deactivated and we are now in a period of edits being graded.
Volunteers across several language Wikis have begun to evaluate both human generated and machine assisted article short descriptions.
We express our sincere gratitude and appreciation to all the volunteers, and have added a dedicated section to honor their efforts on the project page. Thank you for your support!
We are still welcoming support from the following language Wikipedias for grading: Arabic, English, French, German, Italian, Japanese, Russian, Spanish, and Turkish languages.
If you are interested in joining us for this incredible project, please reach out to Amal Ramadan. We look forward to collaborating with passionate individuals like you!
April 2023: FAQ Page and Model Card
We released our experiment in the 25 mBART languages this month and it will run until mid-May. Prior to release we added a model card to our FAQ page to provide transparency into how the model works.
-
 Suggested edits home
Suggested edits home -
 Suggested edits feed
Suggested edits feed -
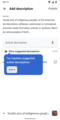 Suggested edits onboarding
Suggested edits onboarding -
 Active text field
Active text field -
 Dialog Box
Dialog Box -
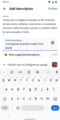 What happens after tapping suggestions
What happens after tapping suggestions -
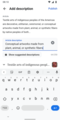 Manual text addition
Manual text addition -
 The preview
The preview -
 Tapping the report flag
Tapping the report flag -
 Confirmation
Confirmation -
 Gender bias support text
Gender bias support text











This is the onboarding process:
-
 Article Descriptions Onboarding
Article Descriptions Onboarding -
 Keep it short
Keep it short -
 Machine Suggestions
Machine Suggestions -
 Tooltip
Tooltip




January 2023: Updated Designs
After determining that the suggestions could be embedded in the existing article short descriptions task the Android team made updates to our design.
-
 Tooltip to as onboarding of feature
Tooltip to as onboarding of feature -
 Once the tooltip is dismissed the keyboard becomes active
Once the tooltip is dismissed the keyboard becomes active -
 Dialog appears with suggestions when users tap "show suggested descriptions"
Dialog appears with suggestions when users tap "show suggested descriptions" -
 Tapping a suggestion populates text field and publish button becomes active
Tapping a suggestion populates text field and publish button becomes active




If a user reports a suggestion, they will see the same dialog as we proposed in our August 2022 update as the what will be seen if someone clicks Not Sure.
This new design does mean we will allow users to publish their edits, as they would be able to without the machine generated suggestions. However, our team will patrol the edits that are made through this experiment to ensure we do not overwhelm volunteer patrollers. Additionally, new users will not receive suggestions for Biographies of Living Persons.
November 2022: API Development
The Research team put the model on toolforge and tested the performance of the API. Initial insights found that it took 5-10 seconds to generate suggestions, which also varied depending on how many suggestions were being shown. Performance improved as the number of suggestions generated decreased. Ways of addressing this problem was by preloading some suggestions, restricting the number of suggestions shown when integrated into article short descriptions, and altering user flows to ensure suggestions can be generated in the background.
August 2022: Initial Design Concepts and Guardrails for Bias
User story for Discovery
When I am using the Wikipedia Android app, am logged in, and discover a tooltip about a new edit feature, I want to be educated about the task, so I can consider trying it out. Open Question: When should this tooltip be seen in relation to other tooltips?
User story for education
When I want to try out the article short descriptions feature, I want to be educated about the task, so my expectations are set correctly.


User story for adding descriptions
When I use the article short descriptions feature, I want to see articles without a description, I want to be presented with two suitable descriptions and an option to add a description of my own, so I can select or add a description for multiple articles in a row.
-
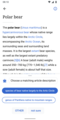 Concept for selecting a suggested article description
Concept for selecting a suggested article description -
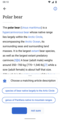 Design concept for a user deciding the description should be an alternative to what is listed
Design concept for a user deciding the description should be an alternative to what is listed -
 Design concept for a user editing a suggestion before hitting publish
Design concept for a user editing a suggestion before hitting publish -
 Design concept for what users see when pressing other
Design concept for what users see when pressing other -
 Screen displaying options for if a user says they are not sure what the correct article description should be
Screen displaying options for if a user says they are not sure what the correct article description should be





Guardrails for bias and harm
The team generated possible guardrails for bias and harm:
- Harm: problematic text recommendations
- Guardrail: blocklist of words never to use
- Guardrail: check for stereotypes – e.g., gendered language + occupations
- Harm: poor quality of recommendations
- Guardrail: minimum amount of information in article
- Guardrail: verify performance by knowledge gap
- Harm: recommendations only for some types of articles
- Guardrail: monitor edit distribution by topic