
Wikimedia Apps/Team/Android/Machine Assisted Article Descriptions/Updates
Updates
[edit]Further changes
[edit]- We've used the same underlying machine-learning model for all of these experiments (so no re-training etc. of the actual model). What we've been adjusting throughout is how the user interacts with it.
- Our initial offline evaluation was of this model (Jan-April '23) lead us to put in place a few modifications to how users interacted with the model for the May-June 2023 piloting -- notably which outputs they could see (only higher confidence ones) and adjusting who could see the recommendations based on whether the article was a biography of a living person or not.
- The feedback from that pilot lead to us putting in place one final adjustment having to do with when a recommended article description included a year in it (only show it if there's support for that year in the article text because this was one source of hallucinations by the model). That's now part of the officially deployed model on LiftWing (the link I shared above) that Android users would see.
- At this point we aren't planning on any model updates beyond trying to reduce the latency of the model so Android users can see the recommendations more quickly. If we got feedback about errors that we thought we could address though, we'd try to make those fixes
August 2024
[edit]- We are beginning to reach out to some Wikis to implement the feature, based on the results from the experiment that was updated and published last January.
July 2024: API available through LiftWing
[edit]We appreciate everyone's patience as we've worked with the Machine Learning team to migrate the model to LiftWing. In August we will clean up the client side code to remove test conditions and add in improvements mentioned in the January 2024 update. In the following months we will reach out to different language communities to make the feature available to them in the app.
If you are a developer and would like to build a gadget using the API, you can read the documentation here.
January 2024: Results of Experiment
[edit]Languages Included in grading:
[edit]- Arabic
- Czech
- German
- English
- Spanish
- French
- Gujarati
- Hindi
- Italian
- Japanese
- Russian
- Turkish
Additional languages monitored by staff that did not have community graders:
- Finnish
- Kazakh
- Korean
- Burmese
- Dutch
- Romanian
- Vietnamese
Was there a difference between Machine Accepted and Human Generated Edit Average and Median Grades:
[edit]| Graded Edits | Avg Grade | Median Grade |
| Machine Accepted Edits | 4.1 | 5 |
| Human Generated Edits | 4.2 | 5 |
- Note: 5 was the highest possible score
How did the model hold up across languages?
[edit]| Language | Machine Accepted
Edits Avg. Grade |
Human Generated
Edits Avg. Grade |
Machine Avg.
Grade Higher? |
Recommendation of if feature should be enabled |
| ar* | 2.8 | 2.1 | TRUE | No |
| cs | 4.5 | Not Applicable | Yes | |
| de | 3.9 | 4.1 | FALSE | 50+ Edits Required |
| en | 4.0 | 4.5 | FALSE | 50+ Edits Required |
| es | 4.5 | 4.1 | TRUE | Yes |
| fr | 4.0 | 4.1 | FALSE | 50+ Edits Required |
| gu* | 1.0 | Not Applicable | No | |
| hi | 3.8 | Not Applicable | 50+ Edits Required | |
| it | 4.2 | 4.4 | FALSE | 50+ Edits Required |
| ja | 4.0 | 4.5 | FALSE | 50+ Edits Required |
| ru | 4.7 | 4.3 | TRUE | Yes |
| tr | 3.8 | 3.4 | TRUE | Yes |
| Other language communities | Not Applicable | Not Applicable | Not Applicable | Can be enabled upon request |
- Note: We will not enable the feature without engaging communities first.
* Indicates language communities where there weren’t many suggestions to grade which we believe had an impact on the score
How often were Machine Suggestions Accepted, Modified or Rejected?
[edit]| Edit type | % of Total Machine Edits |
| Machine suggestion accepted | 23.49% |
| Machine suggestion modified | 14.49% |
| Machine suggestion rejected | 62.02% |
- Note: Rejection means the machine suggestion was not selected though it was available. Machine suggestions were behind an affordance that read "Machine Suggestions". Users that did not view the machine suggestions at all would count in the "rejected" bucket. Rejected is intended to communicate the user had a preference of typing out their article short description instead.
What was the distribution of Machine Accepted Article short Descriptions with a score of 3 or higher?
[edit]| Score | Percent Distribution |
| < 3 | 10.0% |
| >= 3 | 90.0% |
How did the Machine Accepted Article short Descriptions scoring change when taking editor experience into account?
[edit]| Editor Experience | Average Edit Grade | Median Edit Grade |
| Under 50 Edits | 3.6 | 4 |
| Over 50 Edits | 4.4 | 5 |
Our experiment tested two beams to see which was more accurate and performant. To avoid bias, the placement of the suggestion to the user switched positions each time. The results are:
[edit]| Beam Selected | Average Edit Grade | % Distribution |
| 1 | 4.2 | 64.7% |
| 2 | 4.0 | 35.3% |
- Note: When rereleasing the feature we will only display beam 1.
How often are people making edits (modifications) to the machine suggestion before publishing?
[edit]| Edit Type | Modification Distribution |
| Machine Accepted Not Modified | 61.85% |
| Machine Accepted Modified | 38.15% |
How do users modifying the machine suggestion impact accuracy?
[edit]| Machine Graded Edits | Avg. Score |
| Not Modified | 4.2 |
| Modified | 4.1 |
- Note: Due to there not being an impact on accuracy if a user modifies the suggestion or not we do not see a need to require users to make a change to the recommendation, but we should still maintain a UI that encourages edits to the machine suggestion
How often did a grader say they would revert vs rewrite an edit based on if it was Machine Suggested or Human Generated?
[edit]| Graded Edits: | % edits would revert | % edits would rewrite |
| Editor accepted suggestion | 2.3% | 25.0% |
| Editor saw suggestion but wrote out their own description instead | 5.7% | 38.4% |
| Human edit no exposure to suggestion | 15.0% | 25.8% |
- Note: We defined revert as the edit is so inaccurate it is not worth trying to make a minor modification to improve it as a patroller. Rewrite was defined as a patroller would just modify what was published by the user to improve it. Over the course of the experiment only 20 machine edits were reverted across all projects, which was not statistically significant so we could not compare actual reverts, instead we went based on recommendations by graders. Only two language communities have their article short descriptions live on Wikipedia, which means patrolling is less frequent for most language communities due to descriptions being hosted on Wikidata.
What insights did we gain through the feature’s report function?
[edit]0.5% of unique users reported the feature. Below is a distribution of the type of feedback we received:
| Feedback/Response | % Distribution of feedback |
| Not enough info | 43% |
| Inappropriate suggestion | 21% |
| Incorrect dates | 14% |
| Cannot see description | 7% |
| "Unnecessary hook" | 7% |
| Faulty spelling | 7% |
Does the feature have an impact on retention?
[edit]| Retention Period | Group 0
(No treatment) |
Groups 1 and 2 |
| 1-day average return rate: | 35.4% | 34.9% |
| 3-day average return rate: | 29.5% | 30.3% |
| 7-day average return rate: | 22.6% | 24.1% |
| 14-day average return rate: | 14.7% | 15.8% |
- Note: Users exposed to Machine Assisted Article short Descriptions had a marginally higher return rate as compared to users not exposed to the feature
Next Steps:
[edit]The experiment was run on Cloud Services, which is not a sustainable solution. There are enough positive indicators to make the feature available to communities that desire it. The apps team will work in partnership with our Machine Learning to migrate the model to Liftwing, once it has been migrated and sufficiently tested for performance, we will re-engage our language communities to determine where to enable the feature and what additional improvements can be made to the model. Modifications that are currently top of mind include:
- Restrain Biographies of Living Persons (BLP): During the experiment we allowed users with over 50 edits to add descriptions to Biographies of Living Persons with the help of Machine Assistance. We recognize there are concerns about permanently suggesting article short descriptions on these articles. While we did not see evidence of issues related to Biographies of Living Persons, we are happy to not show suggestions on BLPs.
- Only use Beam 1: Beam 1 consistently outperformed Beam 2 when it came to suggestions. As a result, we will only show one recommendation, and it will be from Beam 1.
- Modify Onboarding & Guidance: During the experiment we had an onboarding screen about machine suggestions. We would add back in guidance around machine suggestions when rereleasing the feature. It would be helpful to hear feedback from the community about what guidance they would like us to provide to users about writing effective article short descriptions so that we can improve onboarding.
If there are other obvious errors, please leave a message on our project talk page so that we can address it. An example of an obvious error is displaying incorrect dates. We noticed this error during testing on the app and added a filter that prevents recommendations descriptions that include dates that are not mentioned themselves in the article text. We also noticed that disambiguation pages were recommended by the original model, and filtered out disambiguation pages client side, which is a change we plan to maintain. Other things such as capitalization of the first letter would also be a general fix that we could do because there is a clear heuristic we could use to implement it.
For languages where the model is not performing well enough to deploy, the most useful thing is adding more article short descriptions in that language so that retraining of the model will have more data to go on. There isn't a set date or frequency at this point, however, for which the model will be retrained but we can work with the Research and Machine Learning team to get this prioritized as communities request it.
July 2023: Early Insights from 32 Days of Data Analysis: Grading Scores and Editing Patterns
[edit]We can not complete our data analysis until all entries have been graded so that we have an accurate grading score. However we do have early insights we can share. These insights are based on 32 days of data:
- 3968 Articles with Machine Edits were exposed to 375 editors.
- Note: Exposed does not mean selected.
- 2125 Machine edits were published by 256 editors
- Editors with 50+ edits completed three times the amount of edits per unique compared to editors with less than 50 edits
May 2023: Experiment Deactivated & Volunteers Evaluate Article Short Descriptions
[edit]The experiment has officially been deactivated and we are now in a period of edits being graded.
Volunteers across several language Wikis have begun to evaluate both human generated and machine assisted article short descriptions.
We express our sincere gratitude and appreciation to all the volunteers, and have added a dedicated section to honor their efforts on the project page. Thank you for your support!
We are still welcoming support from the following language Wikipedias for grading: Arabic, English, French, German, Italian, Japanese, Russian, Spanish, and Turkish languages.
If you are interested in joining us for this incredible project, please reach out to Amal Ramadan. We look forward to collaborating with passionate individuals like you!
April 2023: FAQ Page and Model Card
[edit]We released our experiment in the 25 mBART languages this month and it will run until mid-May. Prior to release we added a model card to our FAQ page to provide transparency into how the model works.
-
 Suggested edits home
Suggested edits home -
 Suggested edits feed
Suggested edits feed -
 Suggested edits onboarding
Suggested edits onboarding -
 Active text field
Active text field -
 Dialog Box
Dialog Box -
 What happens after tapping suggestions
What happens after tapping suggestions -
 Manual text addition
Manual text addition -
 The preview
The preview -
 Tapping the report flag
Tapping the report flag -
 Confirmation
Confirmation -
 Gender bias support text
Gender bias support text











This is the onboarding process:
-
 Article Descriptions Onboarding
Article Descriptions Onboarding -
 Keep it short
Keep it short -
 Machine Suggestions
Machine Suggestions -
 Tooltip
Tooltip




January 2023: Updated Designs
[edit]After determining that the suggestions could be embedded in the existing article short descriptions task the Android team made updates to our design.
-
 Tooltip to as onboarding of feature
Tooltip to as onboarding of feature -
 Once the tooltip is dismissed the keyboard becomes active
Once the tooltip is dismissed the keyboard becomes active -
 Dialog appears with suggestions when users tap "show suggested descriptions"
Dialog appears with suggestions when users tap "show suggested descriptions" -
 Tapping a suggestion populates text field and publish button becomes active
Tapping a suggestion populates text field and publish button becomes active




If a user reports a suggestion, they will see the same dialog as we proposed in our August 2022 update as the what will be seen if someone clicks Not Sure.
This new design does mean we will allow users to publish their edits, as they would be able to without the machine generated suggestions. However, our team will patrol the edits that are made through this experiment to ensure we do not overwhelm volunteer patrollers. Additionally, new users will not receive suggestions for Biographies of Living Persons.
November 2022: API Development
[edit]The Research team put the model on toolforge and tested the performance of the API. Initial insights found that it took 5-10 seconds to generate suggestions, which also varied depending on how many suggestions were being shown. Performance improved as the number of suggestions generated decreased. Ways of addressing this problem was by preloading some suggestions, restricting the number of suggestions shown when integrated into article short descriptions, and altering user flows to ensure suggestions can be generated in the background.
August 2022: Initial Design Concepts and Guardrails for Bias
[edit]User story for Discovery
When I am using the Wikipedia Android app, am logged in, and discover a tooltip about a new edit feature, I want to be educated about the task, so I can consider trying it out. Open Question: When should this tooltip be seen in relation to other tooltips?
User story for education
When I want to try out the article short descriptions feature, I want to be educated about the task, so my expectations are set correctly.


User story for adding descriptions
When I use the article short descriptions feature, I want to see articles without a description, I want to be presented with two suitable descriptions and an option to add a description of my own, so I can select or add a description for multiple articles in a row.
-
 Concept for selecting a suggested article description
Concept for selecting a suggested article description -
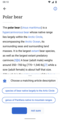 Design concept for a user deciding the description should be an alternative to what is listed
Design concept for a user deciding the description should be an alternative to what is listed -
 Design concept for a user editing a suggestion before hitting publish
Design concept for a user editing a suggestion before hitting publish -
 Design concept for what users see when pressing other
Design concept for what users see when pressing other -
 Screen displaying options for if a user says they are not sure what the correct article description should be
Screen displaying options for if a user says they are not sure what the correct article description should be





Guardrails for bias and harm
[edit]The team generated possible guardrails for bias and harm:
- Harm: problematic text recommendations
- Guardrail: blocklist of words never to use
- Guardrail: check for stereotypes – e.g., gendered language + occupations
- Harm: poor quality of recommendations
- Guardrail: minimum amount of information in article
- Guardrail: verify performance by knowledge gap
- Harm: recommendations only for some types of articles
- Guardrail: monitor edit distribution by topic