
CAPTCHA
Les CAPTCHAs (raccourci de Completely Automated Public Turing test to tell Computers and Humans Apart) sont utilisés sur les wikis Wikimedia, via l'extension ConfirmEdit, comme moyen d'empêcher le spam autant que possible, et de démasquer les spammeurs. Sur la plupart des wikis, un utilisateur peut rencontrer un CAPTCHA quand il essaie de créer un compte, une nouvelle page, ou quand il ajoute un lien externe sur une page.
Sur le wiki portugais (pt.wiki), de 2008 à 2013, le CAPTCHA a également été temporairement affiché à chaque modification faite par les utilisateurs non enregistrés ou par les nouveaux arrivés, prétenduement pour réduire le vandalisme (voir la discussion et bugzilla:41745).
L'implémentation actuelle des CAPTCHAs pose un certain nombre de problèmes.
- Ils ne sont disponibles qu'en anglais (bugzilla:5309): les mots utilisés dans nos CAPTCHAs, s'ils ont été créés, devraient être dans la langue de l'utilisateur. Un nombre inconnu de nouveaux utilisateurs non anglophones et de modifications sont perdues.
- Ils violent les principes d'accessibilité (bugzilla:4845).
- Ils n'empêchent pas réellement les robots de spammer.
Alternatives pour une implémentation future éventuelle
CAPTCHAs d'images
Les images Captcha n'ont pas besoin de texte à saisir ce qui est pratique avec les mobiles et les problèmes de traduction. Voici quelques idées de Captchas basés sur des images :
- Trouver tous les différents... (voir le prototype). Les images d'une même catégorie... (comme des humains) sont présentées mélangées avec des images d'une autre catégorie (comme des chats). Les humains savent faire la différence. Notez que dans ce cas, la question reste la même (trouver ce qui diffère) et les catégories utilisées ne sont pas montrées à l'utilisateur.
- Trouver toutes les images d'un même type (voir le prototype). Les images de différentes catégories sont présentées ensemble. On demande à l'utilisateur de trouver toutes les images d'un type donné (par exemple, toutes les personnes portant des lunettes).
- Labelliser des images (voir le prototype). Des images sont présentées à l'utilisateur; elles contiennent des éléments qui ont été marqués et des options qui permettent de choisir le libellé correct; par exemple : Est-ce un oiseau? Est-ce un avion ?.
La partie difficile ici est comment créer des images et vérifier les données d'une manière qui ne soit pas exploitable par les robots spammeurs. Vous devez posséder un grand nombre de CAPTCHAs (au mieux des centaines de milliers), sinon il suffit à l'attaquant de calquer la base de données de vos CAPTCHA. Si vous utilisez un dépôt public d'images (tel que Commons), ou une source de données ouvertes (telle que les catégories Commons), il y a des chances que l'attaquant puisse identifier le CAPTCHA et sa source et ainsi trouver la solution.
-
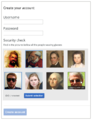 Trouver tous les...
Trouver tous les... -
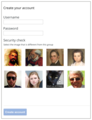 Trouver les différents...
Trouver les différents... -
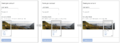 Marquer les sélections...
Marquer les sélections...


Remplacer le CAPTCHA par un pot de miel
Une possibilité pour éviter les problèmes dûs aux langues avec le CAPTCHA est simplement de le supprimer et de le remplacer par un pot de miel.
Un clone de reCAPTCHA élevé à la maison
Ecrivez une version de reCAPTCHA qui utilise des images de documents ayant été traitées par l'extension ProofreadPage de MediaWiki pour Wikisource : WikiCAPTCHA. En d'autre termes, un CAPTCHA fournit des données à ProofreadPage pour renforcer son traitement de reconnaissance de caractères (OCR — Optical Character Recognition). Vous pouvez faire votre construction sur du code existant. Il vaut mieux noter que « reCAPTCHA » n'a pas de licence quant à la technologie présente derrière les algorithmes CAPTCHA textuels (tout au moins aucun qui ne soit discuté sur leur site web ou que l'on puisse trouver sur le site des US Patents & Trademark Office » , selon un bloggeur [1]).
Discuté également au Wikimania 2012 avec la présentation Wikicaptcha: une solution simili ReCAPTCHA pour Wikisource
L'avantage de cette approche est que vous pouvez dédier les tâches plus lentes à la résolution des Captcha, et donner la priorité à un projet Wikimedia (Wikisource); ainsi vous commencez avec un ensemble réduit de données. En fait l'utilisation de reCaptcha permet de créer un ensemble de données de démarrage, puis afficher aux utilisateurs divers captchas résolus et non résolus, et ceux qui le sont vont servir à la vérification alors que les autres seront utilisées pour générer des données supplémentaires. Mais cela n'est pas facile et requiert une attention particulière dans le projet, si vous voulez un système de Captcha qui soit finalement pratique partout.
Accessibilité
L'accessibilité à notre CAPTCHA actuel est très mauvaise. Si les utilisateurs ont des déficiences visuelles, ou s'ils utilisent un lecteur d'écran, les Captcha basés sur du texte leurs sont pratiquement tous inaccessibles. Une poignée de nos plus grands wikis résolvent ce problème en mettant à disposition un système de demande de compte géré par une personne bénévole. Les alternatives telles que les CAPTCHAs d'images violent encore les principes d'accessibilité (bugzilla:4845), donc une solution telle que les CAPTCHA audio peut être envisagée, mais elle-même peut échouer pour des sourd-muets.
Voir aussi
- Admin tools development, le domaine de Wikimedia Engineering responsable pour cela, ainsi que des autres outils
- Bogue 38640
- Création de comptes UX/CAPTCHA
- You (probably) don't need ReCAPTCHA (2019)
- TEDxCMU -- Luis von Ahn -- Duolingo: Le chapitre suivant en matière de calulateur humain
- Discussions récentes :
- Captchas et utilisateurs non anglophones - partie I et partie II
- Réparation des CAPTCHA Wikipedia (3 novembre 2011): « Maintenant que le CAPTCHA Wikipedia a été fonctionnellement cassé par Burzstein et. al. dans leur article "Forces et faiblesses des CAPTCHA basés sur du texte" [...] J'ai retravaillé le script Python de génération d'images CAPTCHA des années 2005 dans le moteur CAPTCHA » – le code est encore en attente de relecteurs.
- Suggestion : remplacer le CAPTCHA par de meilleures approches (juillet 2012)
- Sites web importants qui n'utilisent pas CAPTCHA
- Ressources plus anciennes
- Bots Are Better than Humans at Solving CAPTCHAs (on An Empirical Study & Evaluation of Modern CAPTCHAs, 2023)
- Asirra: un CAPTCHA exploitant la catégorisation manuelle des images classées par intérêt, CCS’07, du 29 octobre au 2 novembre 2007, Alexandria, Virginie, USA (contient des références vers d'autres articles utiles à propos des CAPTCHAs.)
- Philippe Golle. 2008. Attaques de l'apprentissage automatisé sur le Captcha Asirra. Dans Procédures de la 15e conférence de l'ACM sur l'Ordinateur et la sécurité des communications (CCS '08). ACM, New York, NY, USA, 535-542. DOI=10.1145/1455770.1455838